Introduction au Deep Learning
L’Intelligence Artificielle est un domaine de recherche dont l’objectif est de doter les machines de fonctionnalités cognitives similaires à celles des humains. L’apprentissage machine, ou Machine Learning (ML) se différencie du champ de recherche en Intelligence Artificielle symbolique basé sur la logique. Là où ce dernier vise à créer des systèmes décisionnels à partir de lois préexistantes, l’apprentissage machine consiste à déterminer ces lois à partir des données sans qu’elles ne soient explicitement programmées.
Les modèles de Machine Learning sont entraînés pour apprendre de la même manière que les humains quand ils expérimentent le réel. Cela se fait généralement en apprenant à partir d’exemples d’entrées/sorties (apprentissage supervisé) ou en observant des phénomènes pour en tirer des règles (apprentissage non-supervisé), ou bien encore en apprenant par essais/erreurs (apprentissage par renforcement). Le Machine Learning est l’un des principaux domaines de recherche qui permet aux systèmes informatiques d’effectuer des tâches spécifiques d’intelligence artificielle. Ces tâches imitent dans une mesure limitée un comportement dit intelligent, perceptuel ou cognitif.
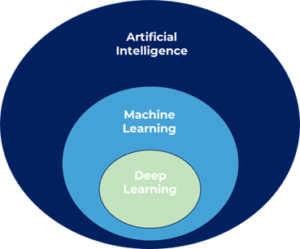
Figure 1. Diagramme de Venn représentant les relations des domaines liés à l’IA.
Récemment, avec la quantité massive de données accessibles publiquement, le domaine du Machine Learning a connu des progrès révolutionnaires grâce à l’essor de l’apprentissage profond par réseaux de neurones, ou Deep Learning (DL).
Les modèles de Deep Learning sont inspirés par la configuration des couches du cortex visuel humain dans les problèmes de vision où, de couches en couches, le signal d’entrée est représenté dans des espaces de plus en plus abstraits jusqu’à aboutir à des représentations sémantiques. Cette notion d’apprentissage de représentation est au cœur des méthodes de Deep Learning.

Figure 2. Le cerveau humain est un extracteur de caractéristiques brillant . [Thorpes & Fabre-Thorpe 2001]
Le Deep Learning, comment ça marche ?
De manière générale, les performances des modèles de Machine Learning dépendent largement de la pertinence et de la fiabilité des représentations des données d’entrée et nécessitent une grande compétence en traitement du signal qui est une étape très importante pour obtenir de bons modèles. Cette expertise des représentations des signaux d’entrée peut être extrêmement complexe et nécessite d’énormes efforts pour les différentes tâches de Machine Learning.
Avant la démonstration empirique de l’efficacité des modèles de Deep Learning, la plupart des systèmes d’analyse de signaux structurés consistaient à écrire à la main des algorithmes de traitement du signal en fonction de la spécificité de chaque domaine pour produire des représentations pertinentes. Des algorithmes de Machine Learning étaient ensuite appliqués sur ces représentations haut niveau pour trouver le modèle ayant les meilleures performances prédictives/descriptives.
Le principal objectif du Deep Learning est d’apprendre des représentations de n’importe quel signal d’entrée en supprimant la nécessité d’écrire à la main ces algorithmes d’extraction de caractéristiques. À la place, l’objectif est d’apprendre une fonction possédant un grand nombre de paramètres ajustables capable de faire directement le lien entre le signal et la prédiction.
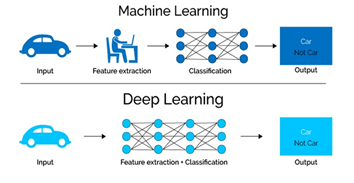
Figure 3. Comparaison entre Machine Learning classique et Deep Learning. Les modèles profonds permettent d’apprendre la procédure d’extraction de caractéristiques utiles des images en plus du modèle de classification s’appliquant sur ces dernières. (source: https://www.umangsoftware.com)
Ces fonctions correspondent à des architectures spécifiques au domaine et possèdent le point commun d’être composées de plusieurs modules paramétrés (appelée couches). Chacun a pour objectif d’extraire des motifs du résultat de la couche précédente et de les combiner ensemble pour obtenir un nouveau signal de sortie. La composition de ces modules apprenables permet de passer de l’extraction de motifs bas niveaux du signal d’entrée (comme des détecteurs de contours pour les images) à des motifs très haut niveau (représentations sémantiques ou des objets similaires auront des représentations proches.).
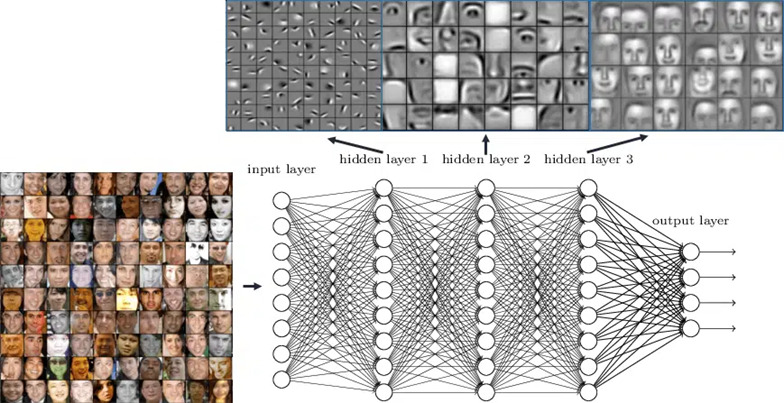
Figure.4 Les différentes couches d’un réseau de neurones profond ainsi que le niveau sémantique des représentations associées. (source : https://www.rsipvision.com/wp-content/uploads/2015/04/Slide6.png)
Dans le cas de la classification d’images, les architectures utilisées sont les réseaux de neurones convolutifs (Convolutional Neural Networks ou CNN) dont les paramètres ajustables correspondent aux poids des filtres de convolution susceptibles de détecter et d’extraire différents motifs visuels locaux. Comme le montre la figure ci-dessous, cascader plusieurs couches de filtres convolutifs et d’opérateurs de sous échantillonnage du signal, permet d’extraire des motifs de plus en plus grande échelle par rapport au signal d’origine et permet d’obtenir un vecteur de représentation global d’une image. L’espace dans lequel vivent ces vecteurs correspond au point d’entrée d’un modèle de classification linéaire classique dont les paramètres sont appris conjointement avec les filtres de convolution en une seule procédure d’optimisation.
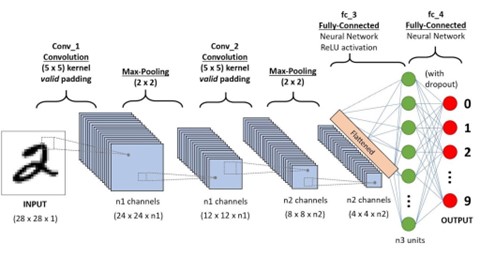
Figure 5. Schéma d’un réseau de neurones profonds convolutifs. (source: https://neptune.ai/blog/understanding-representation-learning-with-autoencoder-everything-you-need-to-know-about-representation-and-feature-learning)
La particularité de ces réseaux de neurones est qu’ils possèdent un très grand nombre de paramètres ajustables et l’objectif est de trouver par un procédé d’optimisation une bonne configuration de ces derniers pour produire en sortie la plus petite erreur de classification possible sur un jeu d’entraînement. Cela revient à trouver, par exemple dans le cas du réseaux convolutif, quels sont les paramètres des filtres qui sont capables d’extraire des motifs qui vont être utiles pour la prédiction de la variable cible. La figure suivante illustre ce principe via une analogie avec une machine dont il faudrait trouver le bon réglage pour qu’elle produise la sortie désirée :
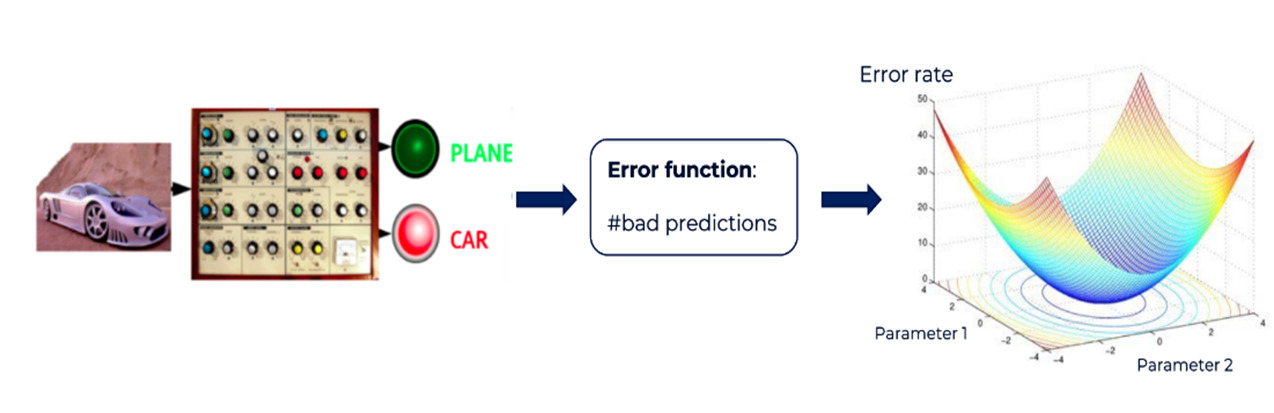
Figure 6. Illustration d’une procédure d’apprentissage par ajustement de paramètres pour minimiser un critère d’erreur.
Une difficulté majeure des méthodes d’apprentissage profond est que ce très grand nombre de paramètres nécessite beaucoup de données d’entraînement pour être capable de généraliser leurs performances sur des nouvelles données. C’est pourquoi les “pratiquants” du Deep Learning utilisent généralement de nombreuses heuristiques pour palier à ce manque de données d’apprentissage. Il est souvent intéressant d’agir au niveau de la préparation du jeu d’entraînement, notamment en réalisant des phases dites d’augmentation de données. Il s’agit d’augmenter virtuellement la taille du jeu d’apprentissage en lui appliquant des transformations aléatoires (eg. Rotation des images). Il est aussi souvent utile de procéder à un nettoyage du bruit ou de certains biais dans les données. Les techniques de régularisation sont aussi beaucoup utilisées pour contraindre la recherche des meilleurs paramètres dans un sous-ensemble des configurations possibles. Enfin, si la tâche cible que l’on veut résoudre possède trop peu de données pour obtenir une bonne capacité de généralisation, il est courant d’utiliser un très grand ensemble d’apprentissage pour apprendre un modèle sur une tache différente de celle ciblée mais partageant de l’information avec cette dernière. Les paramètres du modèle obtenus sont ensuite ajustés en apprenant sur la tache cible en partant des paramètres appris précédemment comme initialisation. Cette procédure porte le nom de Transfert Learning et est aujourd’hui très utilisée dans de nombreux problèmes de Machine Learning.
De nombreuses applications
Depuis quelques années, les modèles CNN ont beaucoup évolué et permettent maintenant d’atteindre des performances de classification d’images parfois supérieures à celles d’experts humains (dans la mesure où un nombre suffisant d’exemples est disponible pour l’entraînement du modèle). La littérature sur les modèles de Deep Learning est maintenant très riche et d’autres types d’architecture existent aussi pour traiter d’autres problèmes que des données images. Notamment, les réseaux de neurones récurrents (RNN) permettent l’analyse de données séquentielles (eg. des sons). Ces derniers ont la capacité de prendre en compte les dépendances temporelles à plus ou moins long terme notamment grâce à leur extension nommée LSTM (Long Short-Term Memory) qui ont permis d’atteindre de très bonnes performances sur des problèmes de reconnaissance vocale dans les années 90.
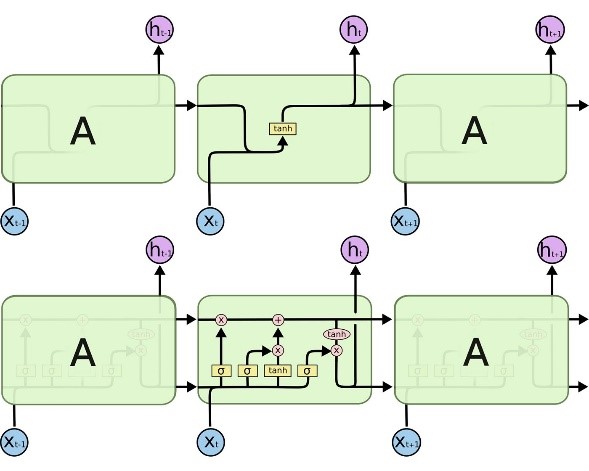
Figure 8. Comparaison entre une architecture de réseaux de neurones classique (haut) avec un réseau LSTM (bas). (source : http://blog.softmaxdata.com/keras-lstm)
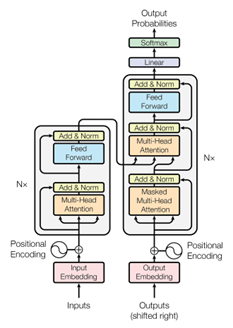
Figure 9. Architecture Transformer. (source: https://arxiv.org/abs/1706.03762)
Il semble cependant qu’une autre catégorie d’architectures à base de couches d’attention appelées Google’s Transformers supplantent leurs prédécesseurs en termes de performances prédictives notamment sur d’autres problématiques telles que le traitement du langage naturel, mais aussi la production de légendes et la détection et localisation d’objet dans les images.
Les espaces de représentation appris par ces modèles ont aussi révolutionné la manière d’explorer et de visualiser rapidement un jeu de donné.es. Comme le montre la Figure 10, il est possible, par le biais de méthodes de réductions de dimensionalité, de projeter des entités multimédias dans un espace de visualisation en 2 dimensions. Dans cet espace, les images représentées par des points proches auront des contenus similaires et des points éloignés correspondront à des images ayant des contenus moins ressemblants.
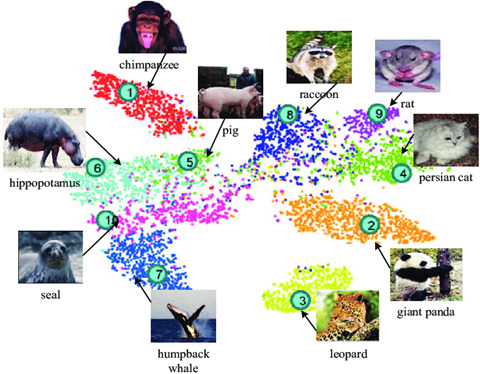
Figure 10. Visualisation d’un jeu de données dans un espace de représentation réduit. (source: https://www.researchgate.net/profile/Zhongfei_Zhang/publication/315667268)
Le Deep Learning chez Seenovate
Suivant de près les avancées récentes autour du Deep Learning, Seenovate renforce et étend ses solutions décisionnelles sur un large champ d’application. Cela nous permet de formuler les besoins actuels et d’anticiper les défis futurs pour adapter nos solutions en vue de meilleures performances. Nous proposons des solutions basées sur le Deep Learning pour adresser plusieurs cas d’usage, notamment dans la détection de maladie à partir d’images du patient et de leur contexte.
Les modèles proposés pour chacune de ces applications prennent en entrée une ou plusieurs images pour l’objet cible avec quelques métadonnées disponibles dans la phase d’acquisition de données. Ces modèles sont conçus pour incorporer dans un pipeline, différents modules tels que la détection d’objets, l’extraction d’arrière-plan et un module de classification et de prédiction de scores. Certains de ces modules sont déjà pré-entraînés et pourraient permettre de transférer la capacité apprise directement à travers de nombreuses tâches en aval, tandis que certains d’entre eux sont optimisés à partir de zéro.
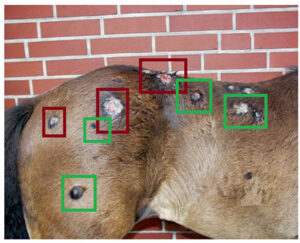
Figure 11. Example factice de modèle de détection et localisation d’objet appliqué à la reconnaissance de pathologie dermatologique.
Seenovate utilise aussi des modèles de Deep Learning de pointe pour gérer des ensembles de données séquentiels tels que des données textuelles. À l’instar des problèmes de vision par ordinateur, nous utilisons des modèles d’attention de type Transformers pré-entraînés pour la modélisation du langage. Ces modèles pourraient être affinés pour de nombreuses tâches en aval et pour de nombreuses langues. L’un des cas d’utilisation importants pour cela est la classification de texte dans des conditions extrêmement limitées où très peu de données annotées – parfois aucune – sont disponibles.
Seenovate accorde une attention particulière non seulement à la recherche expérimentale en apprentissage profond, mais aussi à de nombreuses questions ouvertes de recherche. La capacité de généralisation des modèles, l’amélioration de qualité des données annotées utilisées dans l’entraînement de ces modèles, la modélisation de l’incertitude du processus d’annotation lui-même et la façon de l’intégrer dans le processus d’apprentissage sont tant de sujets de recherche sur lesquels nos experts concentrent leurs travaux et qui font de Seenovate le choix idéal pour résoudre les tâches prédictives les plus complexes avec le minimum d’exemples d’entraînement.
Par ailleurs, comme les modèles de Deep Learning consistent à optimiser une fonction possédant un très grand nombre de paramètres (parfois des milliards), ils requièrent une puissance de calcul supérieure à celle de simples machines dotées uniquement des unités de calcul classique (CPU). En pratique, il est nécessaire pour apprendre ces modèles de les déployer sur des structures de calculs pouvant effectuer un grand nombre d’opérations en parallèle, comme des cartes à processeurs graphiques (GPU). Chez Seenovate, nous entraînons nos modèles en utilisant différents services cloud comme par exemple Google Cloud Platform (GCP), Microsoft Azure, Amazon Web Services (AWS).
Contactez-nous pour plus d’informations sur nos projets Deep Learning !



