Qu’est-ce que SAP Hana ?
SAP HANA est la pierre angulaire de l’écosystème SAP, servant de base de données centrale pour une gamme variée de solutions, y compris les solutions analytiques telles que SAP Analytics Cloud (SAC), les systèmes ERP comme SAP S/4HANA, les entrepôts de données comme SAP Datasphere. Ici, nous allons vous présenter le coeur de cette technologie.
Disponible en versions on-premise ou Cloud, SAP HANA se distingue par son stockage des données. En effet, celles-ci sont stockées en colonnes, ce qui est plus pertinent pour les besoins de la Business Intelligence (BI).
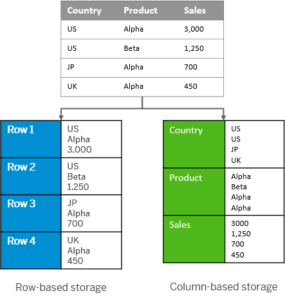
Source image : SAP
Cette approche de stockage présente plusieurs avantages et favorise :
- une forte compression des données de manière automatique.
- les opérations de jointure, agrégation, recherche… sans forcément nécessiter la création d’index supplémentaire.
- la parallélisation des opérations, et donc la vitesse.
La gouvernance de la donnée : Élément clé de SAP HANA
L’un des principes clés de SAP HANA est l’unicité de l’information : on intègre la donnée une seule fois, dans les tables de faits et de dimensions. Cette donnée va ensuite être croisée dans les datamarts via des vues. Les calculs s’effectuent virtuellement et instantanément, éliminant ainsi le besoin de tables d’agrégats traditionnelles.
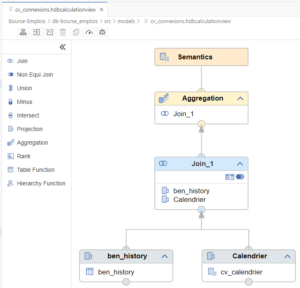
La construction des datamarts repose sur des vues graphiques que l’on appelle « Calculation Views ». Elles offrent des fonctionnalités telles que les jointures, les agrégats, les champs calculés, le comptage…
On distingue les champs de type mesure et ceux de type dimension et on va définir la sémantique avec des labels et des hiérarchies définies dans la base de données. Ils seront ensuite repris par tous les outils de reporting (SAC, SAP BO, PowerBI, Tableau…).
Comme pour une vue SQL, on va pouvoir construire des vues graphiques basées sur d’autres vues graphiques. Cette approche facilite la data gouvernance : une seule source et une donnée affichée toujours à jour.
La performance, et l’accessibilité deux atouts majeurs
En termes de performances, généralement cette modélisation virtuelle permet des temps d’exécution d’environ 250 ms (oui, un quart de seconde). C’est certes plus lent qu’une requête sur une table HANA (3-5ms) mais c’est beaucoup plus rapide à développer que des flux BI et facile à maintenir. Le développement des éléments (tables/vues/flux…) dans HANA implique la création de fichiers, que l’on va ensuite déployer dans la base de données.
Pourquoi ne pas développer directement en SQL ? Parce que ces fichiers vont être versionnés (= mis sur Git) ce qui facilite le suivi des modifications et permet de revenir en arrière en quelques commandes. On pourra même mettre en place un pipeline CI/CD.
De plus, SAP HANA est 100% compatible SQL. L’utilisateur est donc immédiatement familier avec la syntaxe des requêtes et n’a pas à en apprendre une nouvelle. L’outil de développement Business Application Studio est similaire à VS Code, assez commun dans le monde du développement, ce qui facilite d’autant plus l’adoption de cette base.
L’intégration des données passe nativement par un module, Smart Data Access/Intégration, qui permet facilement de se connecter à toutes les bases de données. On pourra réaliser les transformations classiques à l’intégration. La connexion (pour l’intégration ou l’exposition) peut également se faire en JDBC/ODBC, ce qui la rend compatible avec la plupart des solutions du marché.
Allez plus loin avec SAP HANA
Si cette base de données est certifiée compatible ArcGIS, c’est parce qu’elle gère nativement le géospatial (sans installation supplémentaire). On peut faire de nombreuses opérations : afficher les clients qui sont à une certaine distance d’un point de vente (jointure spatiale), filtrer les points qui sont dans une zone, agréger les zones … On va également pouvoir afficher dans SAP Analytics Cloud un autre découpage que le simple maillage administratif.
L’anonymisation des données est un sujet fort dans certains datamarts. La base intègre nativement les méthodes d’anonymisation courantes (confidentialité différentielle, k-Anonymity et l-Anonymity) réalisées à la volée lors de la consultation. Les utilisateurs peuvent ainsi accéder à des agrégats identiques aux données réelles mais sans pouvoir descendre à une maille trop fine (par exemple connaître le salaire d’un collègue). L’anonymisation peut aussi se faire à l’intégration pour répondre aux contraintes RGPD.
Cette base est conçue pour gérer un volume très important de données (de 32Go à +1To de données compressées). Les datascientists vont même pouvoir déporter les calculs dans la base de données et ne télécharger que les résultats. Les algorithmes de Machine Learning (SAP Predictive Analysis Library) sont disponibles en SQL, Python et R.
En résumé, SAP HANA représente une solution complète pour la gestion des données, offrant des performances élevées, une facilité de développement et des fonctionnalités avancées pour répondre aux besoins les plus exigeants des entreprises.
Chez Seenovate, en tant qu’experts de la Data Intelligence depuis près de 17 ans, nous sommes en mesure de vous accompagner dans l’ensemble de vos projet Business Intelligence, de l’étude de votre architecture, à la migration de vos univers en passant par l’optimisation technique et fonctionnelle de votre plateforme. N’hésitez pas à nous contacter !
En savoir + sur l’auteur
 Cet article a été rédigé par Yann Miquel consultant chez Seenovate depuis 2020, référent SAP BTP et SAP Hana.
Cet article a été rédigé par Yann Miquel consultant chez Seenovate depuis 2020, référent SAP BTP et SAP Hana.
Ses objectifs premiers sont la vitesse de traitement et la gouvernance de la donnée dans l’écosystème cloud SAP.